

Chúng ta cần làm như sau:
1. Lấy dữ liệu từ google
Chúng ta sử dụng google takeout để lấy dữ liệu lịch sử của mình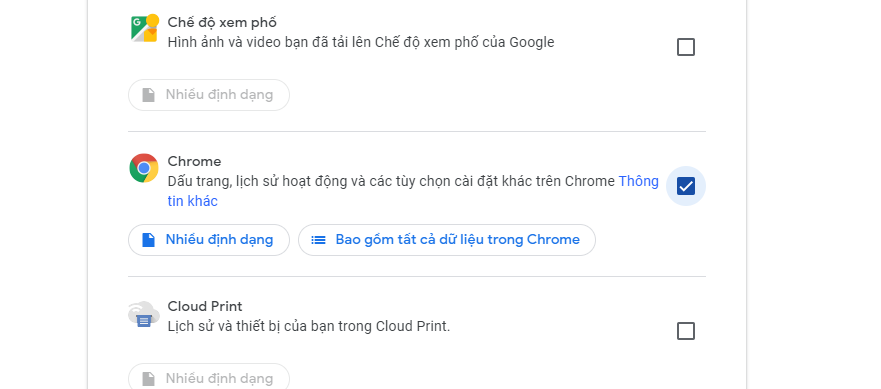
Tiếp theo chúng ta làm theo hướng dẫn của google takeout. Khi hoàn tất chúng ta sẽ nhận được email thông báo từ google. Chúng ta vào link đính kèm email sẽ được như sau: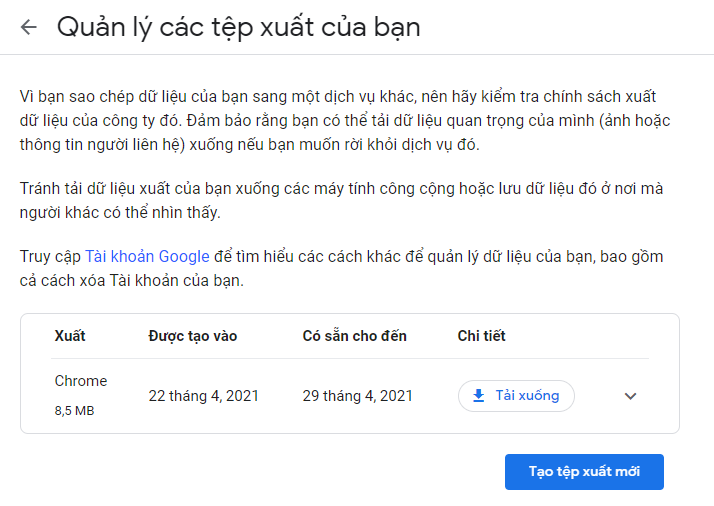
Giờ chúng ta sẽ tải xuống toàn bộ lịch sử web chúng ta truy cập.
Lưu ý: Dữ liệu này sẽ là dữ liệu từ lúc bạn tạo tài khoản google tới lúc hiện tại này. Nếu không thì nó sẽ tích từ lần bạn xoá dữ liệu lịch sử lưu trên google lần cuối.
2. Sử dụng google colab để lọc dữ liệu
Mình sử dụng luôn google colab để xử lý đống này.
Thêm thư viện
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
import seaborn as sns
import matplotlib.pyplot as plt Upload file BrowserHistory.json và đọc nó.
actress = pd.read_json('BrowserHistory.json')
actress.head()

Lọc dữ liệu
df = pd.DataFrame(actress['url'],columns=['url'])
df[df.url.str.contains('.*github.*')].to_json(\"rex.json\",orient='split')
Kết quả là một danh sách các url có từ github trong đó
3. Xử lý trùng lặp và lấy dữ liệu mình cần
Mình mở file rex.json bằng sublime text và bắt đầu sửa.
Đầu tiên chúng ta sẽ format lại đinh dạng để dễ nhìn hơn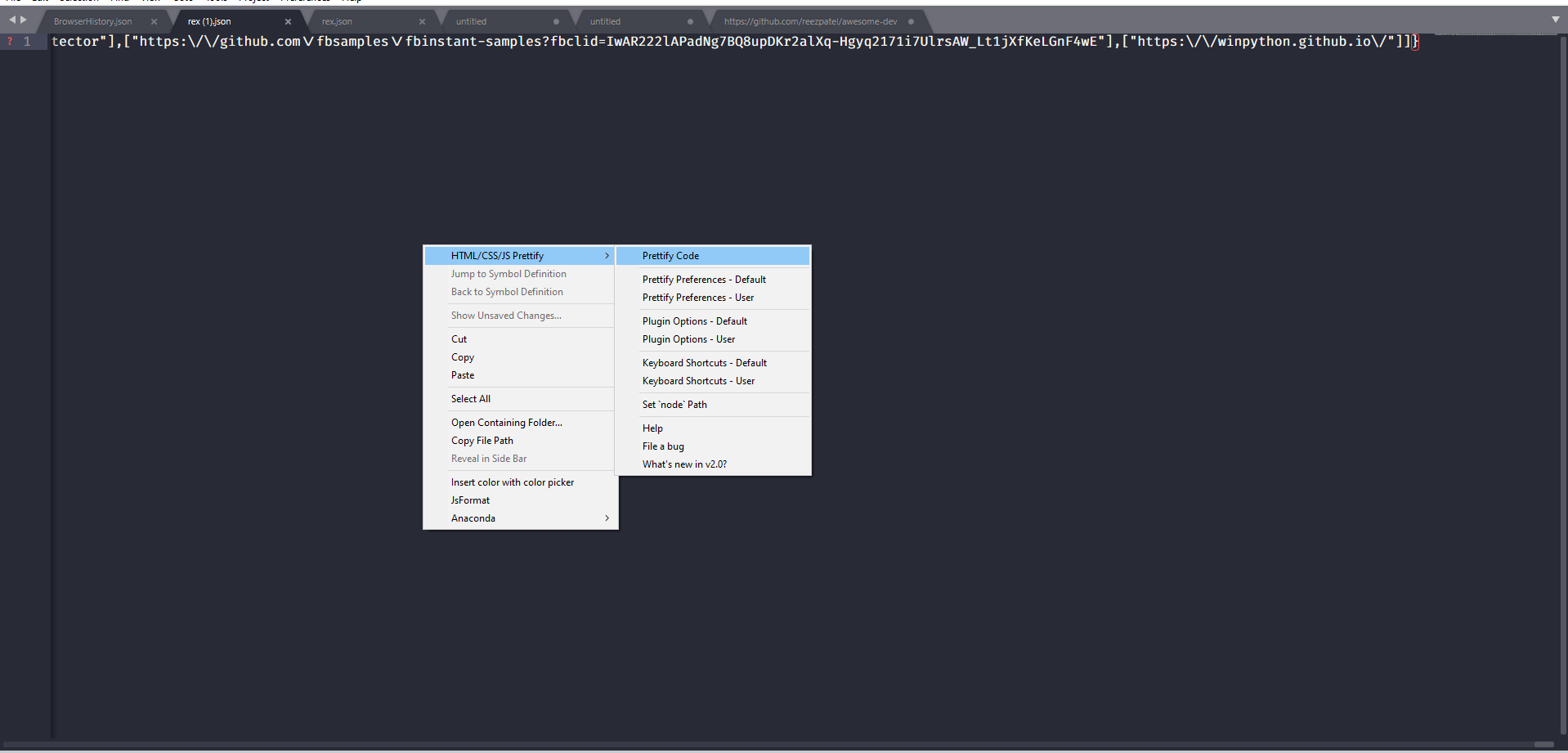
Lấy những url github thoả mãn bằng regex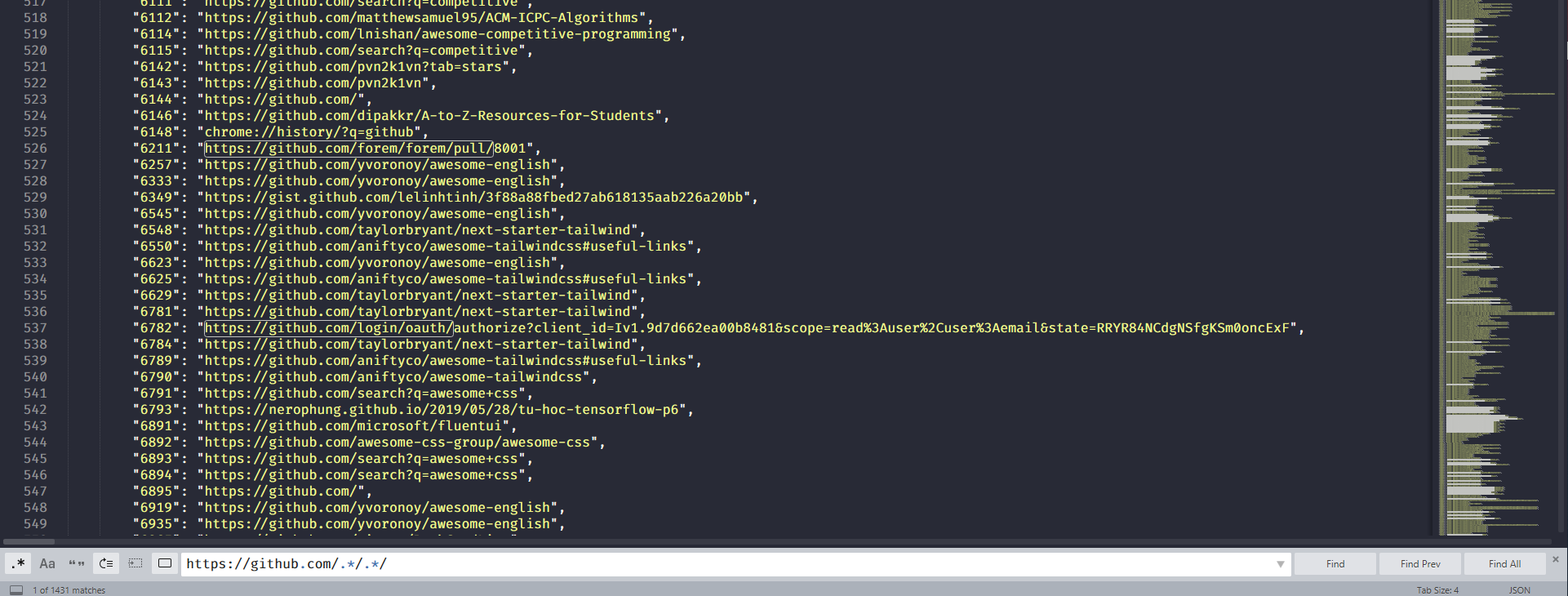
Tiếp là loại bỏ toàn bộ trùng lặp bằng một công cụ online https://codebeautify.org/remove-duplicate-lines
Lúc này dữ liệu đã được loại bỏ trùng lặp nhưng vẫn chưa được như ý. Tôi muốn lấy những repository github thôi thì phải làm sao.
Công cụ tôi nghĩ ngay là excel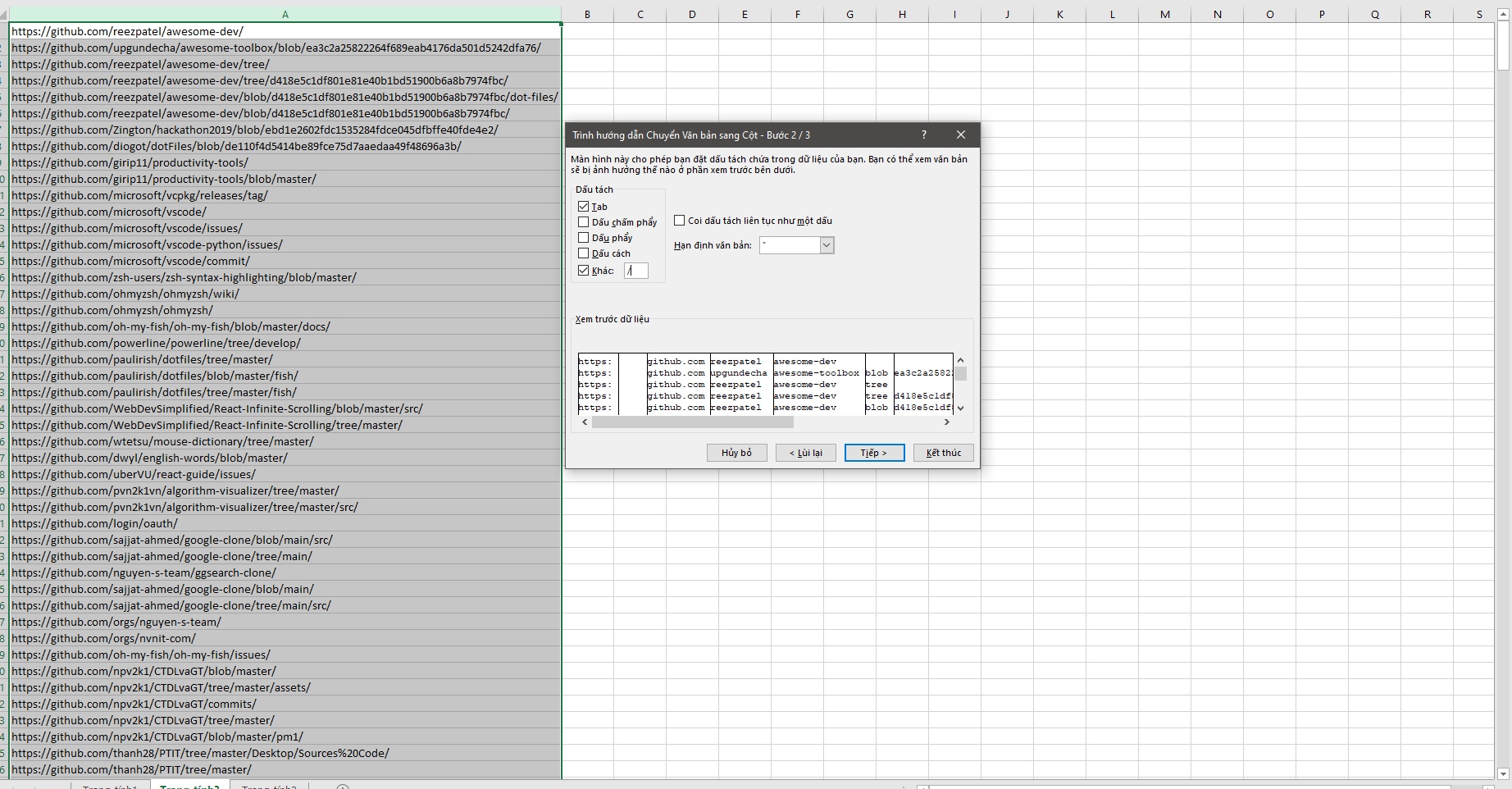
Giờ chúng ta chỉ giữ lại những cột cần dùng và nối chuỗi lại để được kết quả.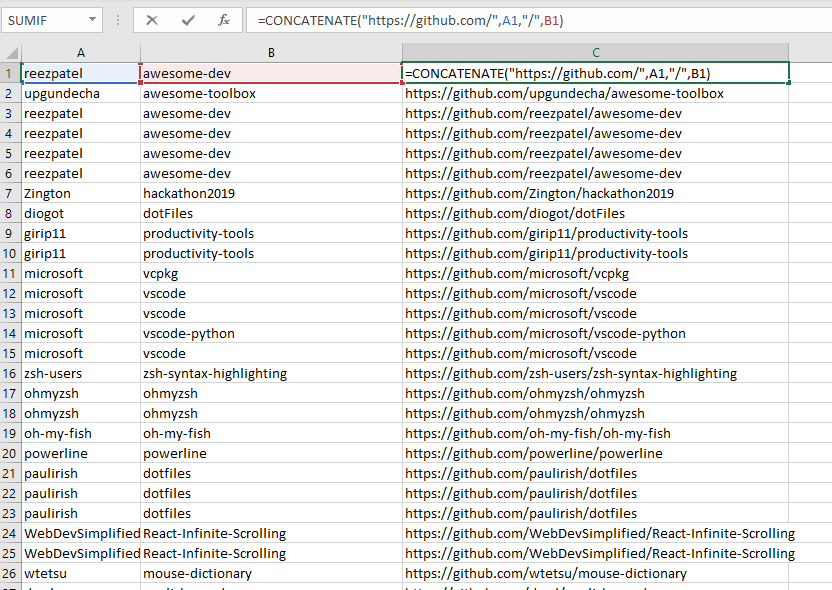
Chúng ta có thể sử dụng công cụ loại bỏ trùng lặp trong excel để loại bỏ những dữ liệu trùng
Đây là kết quả cuối cùng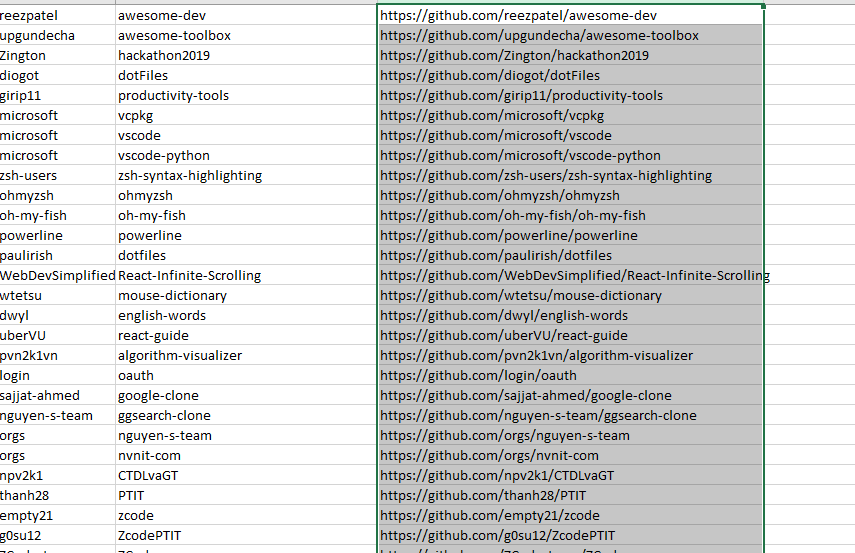
Như vậy chúng ta đã lọc được theo ý mình lịch sử những trang mà mình truy cập.
Cách làm trên thực sự không phải là hoàn hảo nhưng do mình vừa search vừa làm nên nó có chút lộn xộn. Sau này khi học nhiều hơn mình sẽ update những cách tối ưu hơn 😄
Để xử lý những cái trên hiệu quả và thông minh hơn chúng ta nên học thêm về:

